
En avril 2026, ITrust présentait au Forum InCyber (FIC) les résultats d’un projet de recherche mené par son équipe SOC. Thomas Bourthoumieux, Directeur du SOC, et Félix Billières, Analyste SOC N3, ont exposé les travaux conduits par l’équipe N3 et plus largement la Blue Team d’ITrust : intégrer les avancées récentes de l’intelligence artificielle dans le workflow opérationnel du SOC.
Ce projet répond à un constat partagé par l’ensemble de la profession : le cycle purple team classique est trop lent, trop fragmenté et trop peu reproductible pour suivre le rythme des attaquants. L’objectif était de donner à un agent IA les outils, les connaissances et les procédures du SOC, puis de le laisser orchestrer le cycle complet : simulation d’attaque, création de règles de détection, corrélation et documentation, dans une boucle continue.
Cet article prolonge cette conférence sur le plan technique. Il détaille l’architecture construite autour de l’écosystème ITrust et de Reveelium, les choix de conception retenus, et l’impact concret sur le travail des analystes.
Le constat initial
Le cycle purple team, tel qu’il se pratique dans la majorité des SOC, suit un schéma prévisible. La Red Team conduit son audit pendant une semaine. Un rapport PDF est envoyé. Dix jours plus tard, la Blue Team le consulte. Le contexte technique s’est déjà dégradé. Les analystes tentent de reproduire les attaques, écrivent des règles à la main, testent, ajustent face aux faux positifs. La documentation reste généralement non réalisée. Au prochain audit, le cycle repart de zéro.
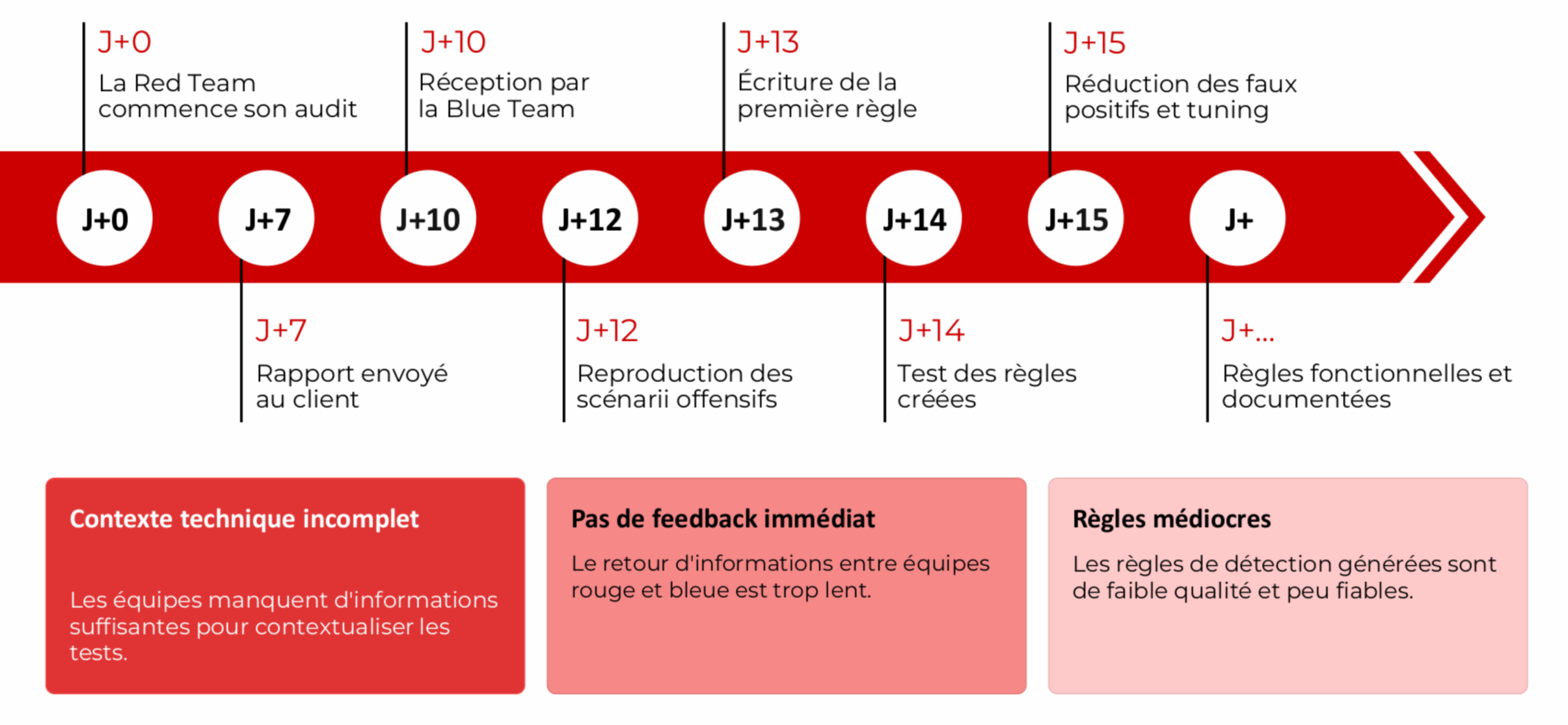
Cycle purple team classique — de J+0 à J+15, contexte incomplet, feedback lent, règles médiocres
Ce n’est pas un problème de compétence. C’est un problème structurel. Un analyste passe sa journée à naviguer entre des outils qui ne communiquent pas : SIEM, collecteur de logs, ticketing, références en ligne, EDR. Chaque transition représente du contexte perdu. Pendant ce temps, les alertes continuent de s’accumuler.
La sécurité offensive dispose de frameworks, d’outils automatisés, de communautés entières qui publient des techniques clé en main. La défense ne disposait pas d’un équivalent. Ce projet vise à en construire un.
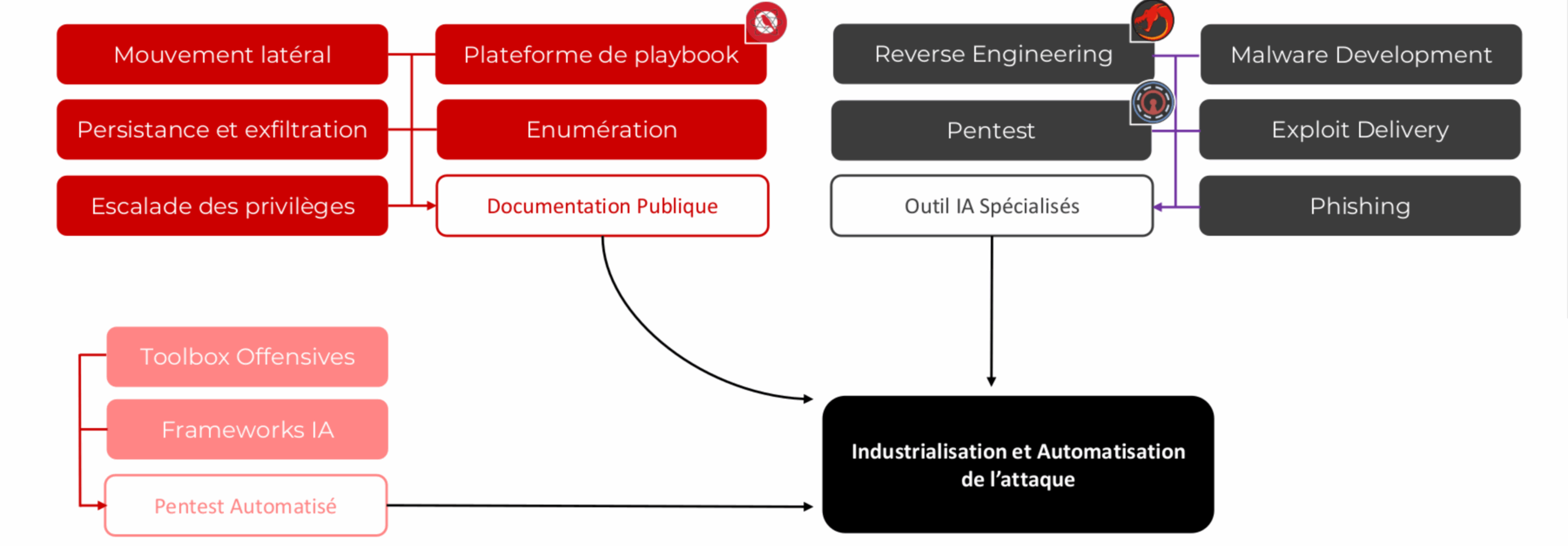
Industrialisation et automatisation de l’attaque — toolbox offensives, frameworks IA, pentest automatisé
Le Model Context Protocol (MCP)
Pour construire cette plateforme, il fallait un moyen de connecter un modèle de langage aux outils de sécurité du SOC. Non pas via des intégrations ad hoc à maintenir une par une, mais via un protocole commun que le modèle puisse interpréter nativement.
Le Model Context Protocol (MCP) est un protocole open source créé par Anthropic. Le principe : chaque outil expose ses capacités via un schéma standardisé, un contrat d’interface que le modèle peut lire et exploiter.
MCP expose deux types de primitives. Les tools sont des fonctions exposées avec une description en langage naturel et un schéma JSON décrivant les paramètres attendus. Quand l’agent dispose d’un tool `search\_logs` qui prend une requête Lucene, une plage temporelle et un nombre de résultats, il sait exactement comment l’utiliser et dans quel contexte l’appeler. Les ressources suivent le même principe, mais en lecture seule : un template de règle avec les champs obligatoires, un inventaire de lab, des profils de menaces. L’agent consulte ces ressources pour calibrer ses décisions avant d’agir.
La valeur de MCP par rapport à un script classique réside dans l’autonomie de décision. Un script enchaîne des étapes prédéfinies. Si l’étape 3 échoue, il s’arrête ou suit une branche prévue à l’avance. L’agent raisonne sur ce qu’il observe. S’il génère une règle qui produit trop de hits, il décide de lancer un cycle de tuning. S’il identifie un pattern multi-étapes dans les logs, il propose une corrélation sans instruction explicite. Le modèle ne déroule pas un pipeline figé : il navigue dans un espace d’outils en fonction du contexte observé.
Architecture : huit serveurs, un orchestrateur
L’implémentation repose sur 8 serveurs MCP indépendants, chacun dans son propre processus Python, communiquant via stdio. L’architecture est de type hub-and-spoke : les serveurs spécialisés exécutent les opérations de terrain, et un orchestrateur central coordonne les workflows multi-plateformes.
Le collecteur de logs interface l’infrastructure de collecte et d’indexation. Il permet la recherche dans des millions d’événements via la syntaxe Lucene, la sélection de flux spécifiques, et la génération de requêtes de détection optimisées.
Reveelium, la plateforme SIEM/UEBA d’ITrust, est au cœur de la détection. Son serveur MCP expose l’accès aux signaux, aux alertes qualifiées, aux menaces (agrégations d’alertes corrélées), aux indicateurs de compromission, aux métriques opérationnelles (MTTD, MTTR) et aux prédictions comportementales. Il expose également la gestion complète des scénarios de corrélation, l’élément clé pour transformer des alertes isolées en incidents qualifiés.
Viserion assure la documentation des campagnes. Chaque action réalisée pendant un exercice purple team est enregistrée dans une campagne traçable et partageable avec l’ensemble de l’équipe.
Exegol connecte les conteneurs offensifs. L’agent peut y exécuter des attaques standardisées (Impacket, Certipy, Rubeus…) dans des environnements de test isolés, sans interaction avec la production.
Caldera et Atomic Red Team couvrent l’émulation d’adversaire : Caldera pour les opérations multi-étapes avec agents persistants, ART pour les tests atomiques unitaires associés à une technique MITRE ATT&CK précise.
Le serveur Rules donne accès à un large corpus de règles de détection existantes, avec recherche par mot-clé, par technique MITRE, par similarité. Il intègre aussi l’analyse de gaps par profil de menace : quelles techniques ne sont pas encore couvertes par le corpus.
L’orchestrateur coordonne l’ensemble. Il expose les outils de haut niveau : génération de règles end-to-end, validation croisée entre le collecteur et Reveelium, création de scénarios de corrélation, audit de couverture MITRE ATT&CK. Il transforme des outils unitaires en workflows cohérents.
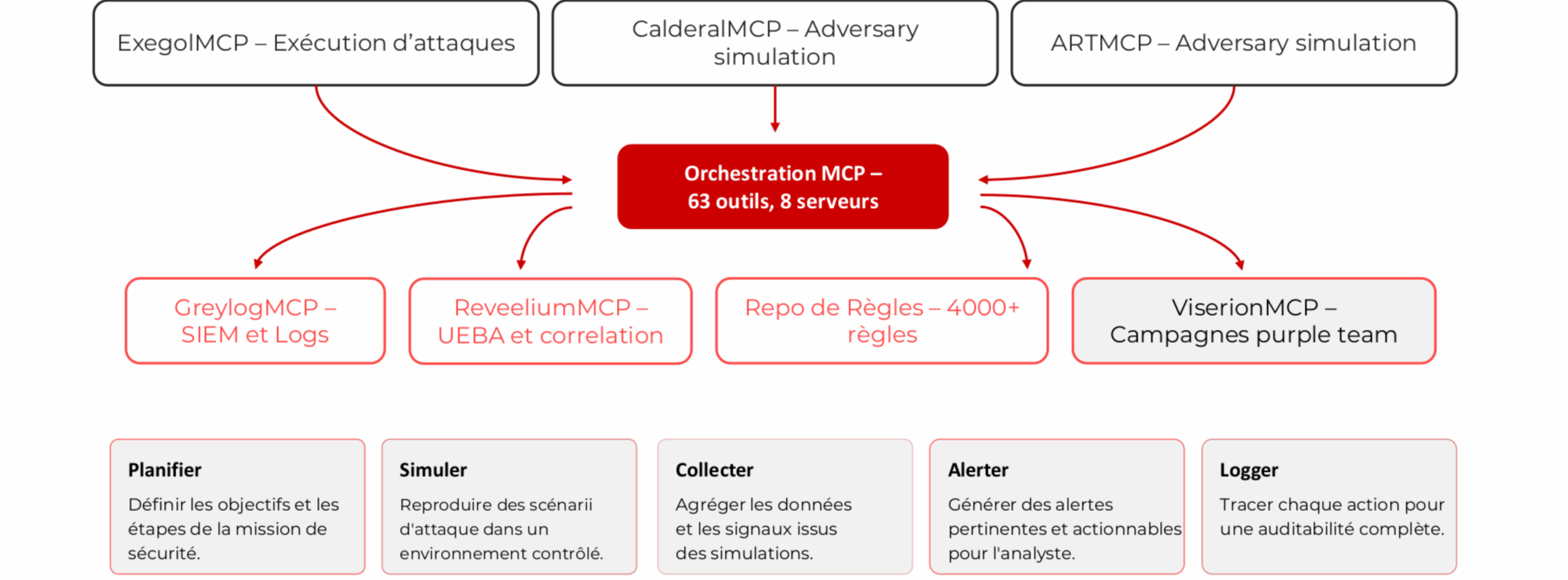
Architecture MCP hub-and-spoke — orchestration centrale, 63 outils, 8 serveurs
Choix d’architecture
Au-delà de la liste des serveurs, ce sont les patterns d’ingénierie qui déterminent la fiabilité et la maintenabilité de la plateforme en conditions réelles.
Factory de serveurs
Avec 8 serveurs MCP, la duplication du code de démarrage serait significative. Une factory unique centralise la création du serveur, l’enregistrement des handlers, la gestion du transport et le nettoyage à l’arrêt. Chaque fichier serveur ne contient que la configuration spécifique à son domaine. L’ajout d’un nouveau serveur se réduit à définir son état, ses outils et sa logique métier.
Registre centralisé
Avec des dizaines d’outils répartis sur 8 serveurs, la cohérence des noms est critique. Un registre centralisé garantit l’unicité de chaque nom d’outil au démarrage et assure le routage des appels vers le bon handler. Ce mécanisme élimine les risques de conflit entre modules qui évolueraient indépendamment.
Composition d’état de l’orchestrateur
Chaque serveur spécialisé possède son propre état : client HTTP authentifié, flux sélectionné, paramètres de session. L’orchestrateur compose tous ces états en un seul objet via héritage multiple de dataclasses. Quand l’orchestrateur se connecte au collecteur de logs puis doit pousser une règle sur Reveelium, les sessions sont déjà disponibles. Pas de ré-authentification, pas de perte de contexte entre les plateformes.
Authentification transparente
Un décorateur vérifie, avant chaque appel d’outil, si le client nécessaire est connecté. S’il ne l’est pas, une connexion automatique est tentée depuis la configuration de l’environnement. Pour l’utilisateur, l’authentification aux différentes plateformes est totalement transparente.
Résilience réseau
Tous les appels HTTP passent par un utilitaire centralisé qui gère le retry avec backoff exponentiel sur les erreurs réseau transitoires, tout en laissant remonter immédiatement les erreurs applicatives.
Impact sur la création de règles
C’est le domaine où l’impact opérationnel est le plus direct. Créer une règle de détection ElastAlert compatible Reveelium implique de renseigner de nombreux champs de métadonnées : UID, sévérité, tactique et technique MITRE, indicateurs de compromission, entité source, cible, TLP, PAP, artifacts. Avant ce projet, le processus complet mobilisait un analyste pendant plusieurs heures.
Pipeline de génération
Le pipeline de génération automatique orchestre plusieurs phases en séquence.
Il commence par récupérer les logs pertinents depuis le collecteur et construire un profil de champs : quels champs sont présents dans les événements, avec quelle fréquence, quelles valeurs. C’est la matière première de la requête de détection.
Un moteur de génération de requête hybride prend ensuite le relais. Il combine deux sources de connaissance : des indices techniques associés aux types d’attaque connus (pour un Kerberoasting, les EventID et types de chiffrement caractéristiques) et une analyse statistique des logs (champs et valeurs surreprésentés dans la fenêtre de l’attaque par rapport au bruit de fond). Le moteur produit un score de confiance qui permet à l’agent de doser la prudence de la validation ultérieure.
La phase suivante résout le profil d’attaque. La plateforme intègre des profils pour les types d’attaque courants (kerberoasting, DCSync, brute force, credential dumping…), chacun spécifiant les champs sémantiques clés : cible, source, IoC pertinents, type de règle recommandé. L’agent sait ainsi que pour un Kerberoasting, le champ discriminant n’est pas le même que pour un lateral movement via PSExec.
Vient ensuite la construction du YAML. Le moteur génère une règle conforme au template officiel, avec l’ensemble des champs Reveelium remplis automatiquement : UID au bon format, résolution MITRE dynamique (tactique et technique), IoC typés, artifacts référençant les champs discriminants. Le mapping MITRE s’appuie sur un index technique maintenu à jour depuis le dépôt STIX officiel.
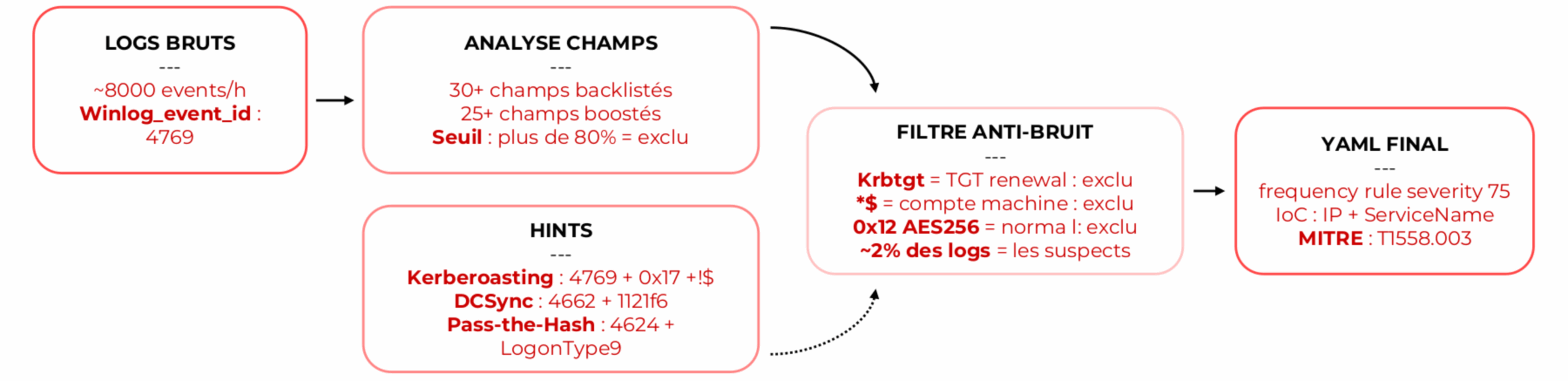
Pipeline de génération — logs bruts, analyse de champs, hints d’attaque, filtre anti-bruit, YAML final
Tuning automatique
Une règle fraîchement générée a rarement les bons seuils du premier coup. Un outil de tuning implémente une boucle de feedback itérative : la règle est testée sur des données réelles via Reveelium, le volume de hits est observé, et les paramètres sont ajustés en conséquence. Trop de bruit : les seuils sont resserrés, des exclusions sont suggérées à partir de l’analyse des résultats. Pas assez de signal : la fenêtre de détection est élargie.
Le principe clé est l’isolation des ajustements : chaque itération ne modifie qu’un seul paramètre, et un diff est généré à chaque pas. L’analyste qui reprend la main dispose de l’historique complet des modifications et de leur justification.
Démonstration
Lors de la conférence, le cycle complet a été présenté en live sur une attaque Golden Ticket : exécution de l’attaque (DCSync, forge du ticket, utilisation), collecte des logs, génération de la règle, et corrélation. L’ensemble a été réalisé en quelques minutes, là où le processus manuel s’étend typiquement sur plusieurs jours.
Corrélation : de l’alerte isolée à l’incident qualifié
Créer des règles unitaires est nécessaire mais insuffisant. Une règle seule génère un signal. Un Kerberoasting isolé peut être un faux positif : un compte de service légitime qui négocie un ticket avec un chiffrement legacy. Ce qui transforme un signal en incident, c’est la corrélation. Et c’est là que Reveelium prend toute sa dimension.
Corrélation par les règles
L’orchestrateur peut prendre une liste de règles existantes, extraire leurs métadonnées (UID Reveelium, tactique MITRE), et pousser un scénario de corrélation sur Reveelium.
Exemple : trois règles couvrent respectivement le DCSync (réplication DRSUAPI), le Golden Ticket (mismatch de chiffrement Kerberos), et la création de service distant. Chacune prise isolément peut générer du bruit. Mais si les trois se déclenchent dans l’ordre, sur le même périmètre, dans une fenêtre temporelle définie, c’est une kill chain complète : Credential Access → Credential Access → Persistence.
Le scénario est poussé sur Reveelium avec un type de corrélation séquentiel, qui impose l’ordre chronologique. Si la séquence complète se produit, Reveelium remonte un incident unique au lieu de trois alertes séparées. L’analyste reçoit une narration structurée de l’attaque, pas trois lignes dans un tableau d’alertes.
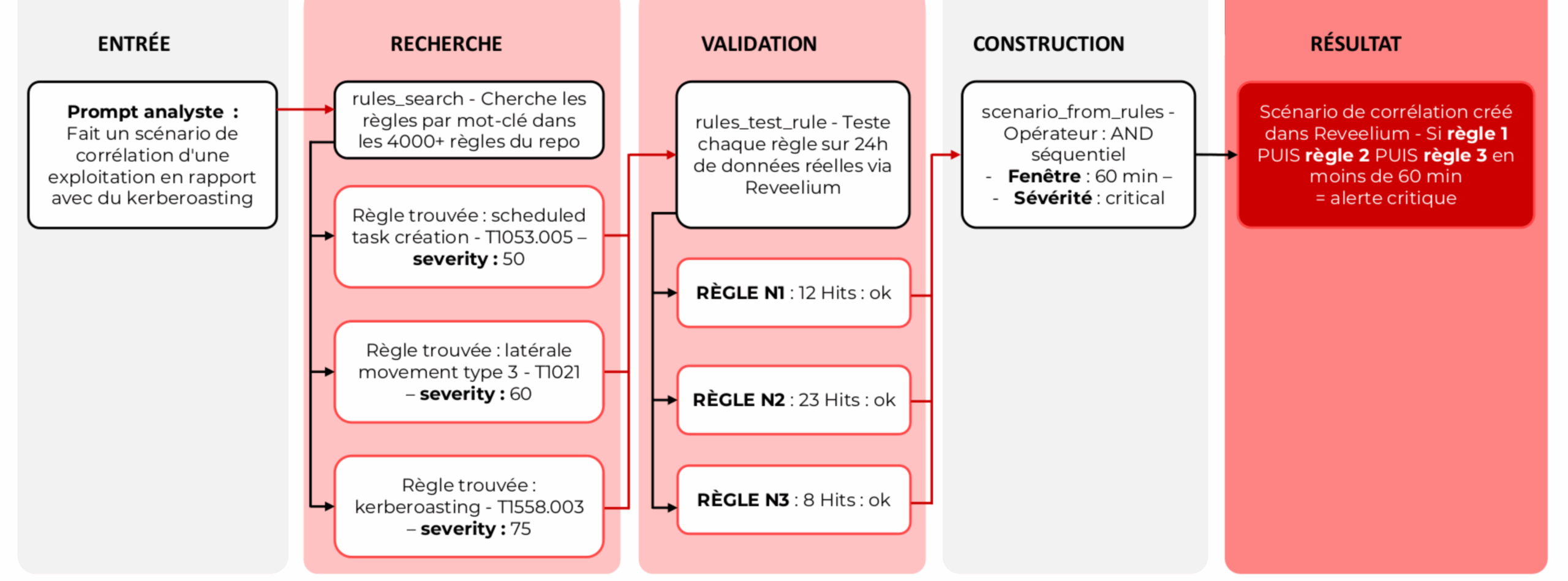
Workflow de corrélation — recherche de règles, validation sur données réelles, construction de scénario Reveelium
Corrélation par les signaux
L’approche inverse est également disponible. À partir des signaux déjà remontés dans Reveelium, le système détecte les patterns automatiquement. Il groupe les signaux par tactique MITRE, identifie les sources qui apparaissent dans plusieurs familles (credential access, lateral movement, persistence…), et peut créer le scénario de corrélation correspondant.
Si une même source déclenche des signaux dans plusieurs familles MITRE distinctes dans une fenêtre courte, le système le détecte et le qualifie. Le résultat : des incidents qualifiés avec une chronologie lisible, plutôt que des alertes dispersées.
Pour un analyste N3, cela change le quotidien de façon significative. Au lieu de corréler manuellement des événements entre différentes interfaces, il reçoit directement des incidents structurés avec leur contexte complet.
Veille CVE : détecter avant l’exploitation
Les mécanismes décrits jusqu’ici partent d’attaques connues rejouées en lab. Mais quand une CVE critique concerne un produit déployé chez un client, le délai entre la publication et le premier exploit public peut être très court. Il faut des règles de détection avant que l’exploit soit dans la nature.
Priorisation intelligente
Le CVSS seul ne suffit pas à prioriser. Le pipeline croise trois sources : le NVD pour les données techniques, le catalogue CISA KEV pour les vulnérabilités activement exploitées, et l’EPSS, un score prédictif estimant la probabilité d’exploitation à court terme. Le scoring composite qui en résulte reflète le risque réel : une CVE avec un score modéré mais une forte probabilité d’exploitation sera traitée en priorité.
Du CWE à la règle de détection
Pour chaque CVE priorisée, le pipeline résout automatiquement la technique MITRE correspondante, principalement via le CWE fourni par le NVD : un CWE-295 (validation de certificat) mappe sur T1557 Adversary-in-the-Middle, un CWE-22 (path traversal) sur T1083 File Discovery. Pour les cas non couverts, une analyse sémantique de la description prend le relais.
Le pipeline catégorise aussi la vulnérabilité par type (RCE, bypass d’authentification, escalade de privilèges…) et par famille de produit (firewall, OS, mail, web, virtualisation…). Chaque catégorie dispose de ses propres stratégies de détection : les index, les champs et les requêtes diffèrent selon qu’il s’agit d’un RCE sur un produit web ou d’un bypass d’authentification sur un firewall.
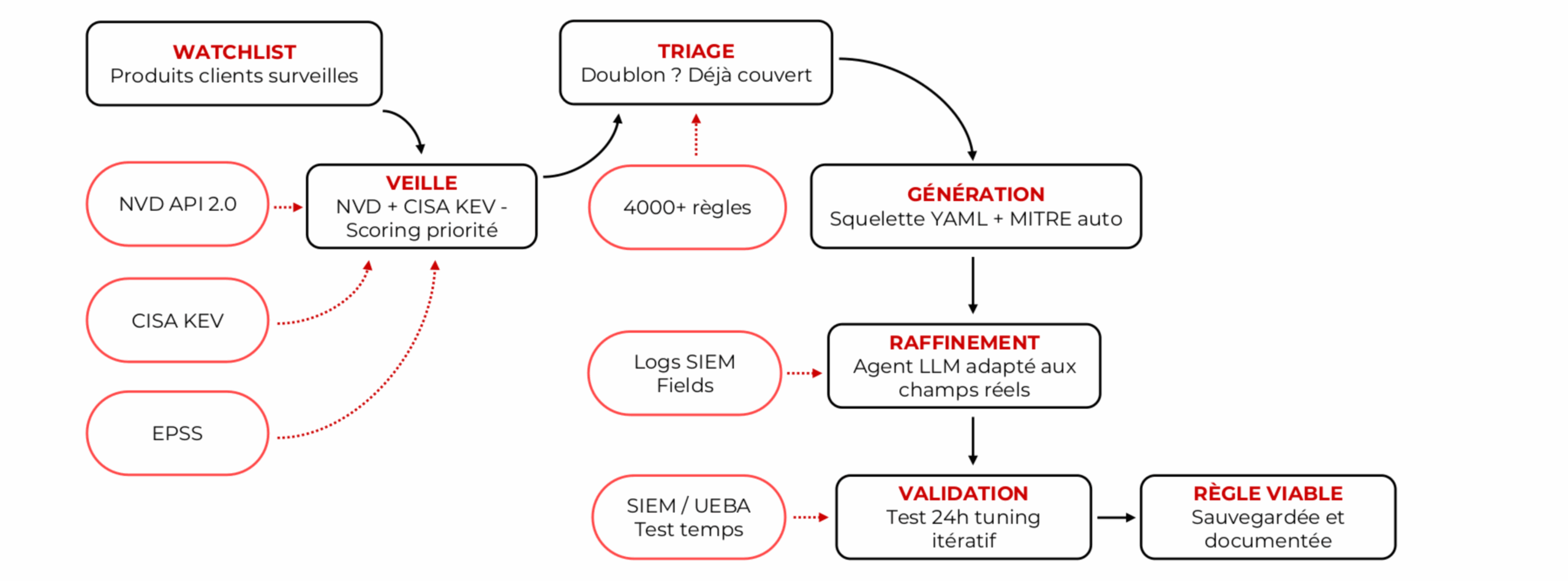
Pipeline veille CVE — watchlist, scoring NVD/KEV/EPSS, triage, génération, validation, règle viable
Le résultat est un squelette de règle ElastAlert avec la requête, l’index, les champs Reveelium et le mapping MITRE appropriés. Ce squelette passe ensuite par le même pipeline de validation et de tuning que les règles issues des exercices purple team.
Lors de la démo au FIC, le public a choisi une CVE, puis des règles supplémentaires ont été générées en rafale. La valeur n’est pas dans la vitesse d’exécution : elle est dans la systématisation. Chaque CVE critique sur un produit surveillé produit une règle candidate prête pour la review humaine.
Réduire l’hallucination : comment l’agent devient un spécialiste
Un point abordé pendant la conférence, souvent sous-estimé dans les approches IA : ce qui fait la différence n’est pas le modèle de langage en soi, mais ce qu’il reçoit comme contexte et comme cadre de travail. Un LLM généraliste, aussi puissant soit-il, va produire des résultats approximatifs s’il doit deviner la structure d’une règle ElastAlert ou le mapping MITRE d’un Kerberoasting. La recherche récente le confirme : l’injection de contexte domaine (grounding, RAG) réduit les hallucinations de 30 à 70 % selon les études, et dans les domaines à haute exigence, cette approche permet d’atteindre des taux d’erreur proches de zéro (JMIR Cancer 2024, MEGA-RAG 2024).
Notre approche repose sur un principe similaire, appliqué au domaine de la détection d’intrusions : contraindre le modèle avec des données vérifiées, des schémas stricts et des boucles de validation, plutôt que le laisser générer en mode libre.
Le handbook : identité et règles absolues
Le fichier de configuration projet est chargé à chaque session. Il ne contient pas de la documentation passive : il définit l’identité de l’agent (analyste SOC N3 avec background offensif), ses règles absolues (jamais de suppositions non vérifiées, jamais de règle sans validation empirique, toujours mapper sur MITRE ATT&CK, choix chirurgical des outils), et un workflow mental imposé : Comprendre → Vérifier → Exécuter → Valider → Itérer.
Ce cadrage est essentiel. La recherche sur le prompting structuré montre des gains de précision de 5 à 15 % par rapport au zero-shot (étude clinique NLP, PMC 2024), et les agents avec des instructions domaine spécifiques surpassent systématiquement les agents généralistes sur les tâches spécialisées (Agentic Context Engineering, arXiv 2025). Ici, le handbook transforme un modèle généraliste en analyste SOC qui pense comme un défenseur avec un background offensif.
Les données de référence : contraindre les sorties
Le deuxième levier contre l’hallucination, c’est la donnée de référence vérifiée. Quand l’agent doit résoudre une technique MITRE, il ne devine pas : il interroge un index dynamique maintenu depuis le dépôt STIX officiel, qui couvre l’ensemble du framework ATT&CK Enterprise. Quand il doit construire une requête de détection pour un Kerberoasting, il dispose de profils d’attaque prédéfinis qui spécifient les champs sémantiques exacts : quel champ représente la cible, quel champ représente la source, quels indicateurs de compromission extraire. Ces profils couvrent les types d’attaque les plus courants en environnement Active Directory et au-delà.
De la même façon, le template de règle ElastAlert officiel, l’inventaire du lab de test, et la watchlist de produits surveillés sont des ressources accessibles à l’agent. Il ne génère pas de noms de champs à partir de sa connaissance générale : il les résout depuis des sources vérifiées. Cette approche correspond au principe du RAG (Retrieval-Augmented Generation), qui selon les méta-analyses récentes améliore la précision factuelle d’environ 40 % par rapport à un LLM utilisé seul (BRICS Economics 2024).
La validation structurelle : falsification systématique
Même avec un bon contexte, un LLM peut produire une sortie syntaxiquement correcte mais sémantiquement incorrecte. C’est pourquoi chaque règle générée passe par une validation structurelle automatique avant toute soumission à Reveelium.
Ce validateur vérifie la présence de tous les champs obligatoires, la conformité des formats (identifiants MITRE, types d’IoC, plages de sévérité), la cohérence entre les champs (les variables référencées dans le texte d’alerte doivent exister dans le dictionnaire de mots-clés), et les contraintes spécifiques au type de règle. Les erreurs auto-corrigeables (alignement d’UID, valeurs hors plage) sont fixées automatiquement. Les erreurs structurelles bloquent la soumission.
Le principe s’apparente à la falsification au sens de Popper : on ne peut pas prouver qu’une règle de détection est correcte (trop de paramètres, trop de dépendance au contexte), mais on peut prouver qu’elle est incorrecte en la confrontant à un ensemble de contraintes connues. Chaque catégorie d’erreur observée en production a été transformée en un critère de falsification supplémentaire. Une règle qui survit à l’ensemble des checks n’est pas « prouvée correcte » : elle est « non réfutée ». Le validateur grandit avec l’expérience, et l’ensemble des contraintes se densifie au fil du temps.
La mémoire : un agent qui s’améliore avec le temps
La mémoire persistante entre les sessions est le mécanisme qui transforme l’agent d’un outil statique en un système qui s’améliore. Après chaque conversation, les informations pertinentes sont sauvegardées par type : feedback utilisateur (corrections d’approche, préférences validées), contexte projet (état des travaux, décisions prises), références externes (emplacements des ressources, dashboards).
Concrètement, quand l’agent a produit une règle qui s’est avérée trop permissive sur un certain type de champ, cette information est enregistrée. La prochaine fois qu’il rencontre un cas similaire, il adapte son approche. Quand un pattern d’attaque a été validé avec succès sur le lab, les détails (commandes exactes, champs discriminants observés, pièges rencontrés) sont mémorisés. L’agent ne redécouvre pas les mêmes solutions et ne reproduit pas les mêmes erreurs.
Ce mécanisme de feedback cumulatif signifie que plus l’agent produit de règles, plus il devient précis. Les profils d’attaque s’enrichissent, les exclusions pertinentes sont mémorisées, les patterns de faux positifs par environnement sont intégrés. C’est un effet de volant d’inertie : chaque itération améliore les suivantes.
Les skills : procédures adaptatives
Les skills complètent ce dispositif en encodant les workflows éprouvés de l’équipe N3 sous forme de texte structuré. Un skill de création de règle impose les étapes clés : vérification de doublons, analyse des logs, génération, validation de conformité, test sur données réelles, sauvegarde. Un skill d’audit de couverture structure l’analyse par profil de menace et génère un plan d’action priorisé. Un skill d’investigation guide le triage SOC depuis les signaux Reveelium jusqu’au verdict.
Mais ces procédures ne sont pas rigides. L’agent interprète le workflow et l’adapte au contexte. Si une étape n’est pas pertinente, il le signale et ajuste. Les études sur les agents avec skills montrent que cette combinaison d’instructions structurées et de flexibilité contextuelle produit de meilleurs résultats que les instructions rigides ou l’absence de structure (Anthropic Agent Skills, 2025).
L’effet cumulé : des couches de défense contre l’erreur
Ces mécanismes ne fonctionnent pas isolément. Ils forment des couches de défense superposées : le handbook cadre le raisonnement, les données de référence contraignent les sorties, la validation structurelle bloque les erreurs, la mémoire capitalise sur l’expérience, et les skills guident les workflows. Si une couche laisse passer une erreur, la suivante la rattrape. C’est, appliqué à la génération de contenu IA, le même principe de défense en profondeur que celui qu’on applique à la sécurité des systèmes d’information.
Garde-fous
Des gains de productivité significatifs ne sont valables que s’ils sont encadrés.
L’agent ne décide jamais seul. Chaque règle générée doit être validée par un humain avant déploiement en production. Les seuils de détection sont subjectifs : chaque SOC et chaque environnement les ajuste différemment. L’agent propose, l’analyste valide.
Le lab est isolé. Toutes les attaques sont exécutées dans des environnements de test (GOAD, conteneurs Exegol). Aucune donnée client, aucun accès production. Cette séparation est structurelle.
Validation empirique obligatoire. Aucune règle ne passe en production sans test sur des données réelles. Les règles sans hits confirmés restent des candidats, pas des règles de production.
Impact opérationnel
Pour un analyste N3, le changement le plus direct est le temps récupéré sur les tâches mécaniques. Au lieu de consacrer des heures à l’écriture YAML manuelle et au copier-coller de requêtes entre interfaces, l’analyste se concentre sur la review critique, l’interprétation des résultats, et les décisions stratégiques.
Pour le SOC, c’est la reproductibilité qui change la donne. Chaque exercice purple team est documenté dans Viserion, chaque règle est tracée, chaque scénario de corrélation est versionné. Le prochain audit ne repart pas de zéro : il repart du dernier état connu. La couverture de détection devient un processus continu.
Pour la veille CVE, le délai entre la publication d’une vulnérabilité et la disponibilité d’une règle de détection se compresse de façon significative. Sur des produits critiques, cette réactivité peut faire la différence entre une détection à l’exploitation et une découverte au post-mortem.
Perspectives
MCP n’est pas un produit ITrust. C’est un protocole open-source, et c’est ce qui rend l’approche extensible. Tout outil de sécurité exposant un serveur MCP devient intégrable dans la boucle : EDR, scanner de vulnérabilités, flux de threat intelligence. Chaque serveur ajouté étend les capacités de l’agent sans modification du reste de l’architecture.
Reveelium, en tant que plateforme centrale de détection et de corrélation, bénéficie directement de cette extensibilité. Chaque nouvelle source de données, chaque nouveau type de signal enrichit la capacité globale de détection. Avec l’orchestration agentique, l’intégration d’une nouvelle source n’est plus un projet de plusieurs semaines : c’est un serveur MCP et quelques outils.
L’attaque dispose d’outils d’IA depuis deux ans. La défense vient de rattraper son retard. Et l’IA ne remplace pas l’analyste : elle lui donne les moyens de travailler à la bonne échelle.
Article rédigé par Félix Billières, avril 2026.
Sources : CrowdStrike Global Threat Report 2026, IBM Cost of Data Breach 2025, Picus Blue Report 2025, SoSafe Cybercrime Trends 2025, SANS Detection Survey 2025, Anthropic MCP.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}